
Issue Creation Diagnostic Tools
Overview
Before an issue is generated, we perform some extra checks. This is so because previously we created issues when we should not have, so we added these checks. Some of these checks are obvious, for example we don't create an issue if one already exists, or if we've never received any data for the system (perhaps because it hasn't been set up properly yet). Some other checks are not so obvious. For example, if a system status is not producing, but new readings are being loaded that indicate that the system is coming back online, then we hold off with issue creation. Also, if readings indicate that data is being bulk-imported (we know this if many readouts are being loaded with the same readout timestamp), then we wait for this to finish before creating an issue. See Review the event log section below for an explanation of how these extra checks are performed.
Another aspect of issue creation is determining how long since the problem started. There are two approaches:
- "straightforward" approach: consider how much time has elapsed since the system status changed to COM ERR or NOT PRODUCING
- "smart" approac: find the last significant readout for the system and consider how much time has elapsed since then
The last "significant readout" is identified based on the system status. If the system is in COM ERR then we haven't been receiving readouts at all, so the last significant readout is the last non-zero readout that we received. If that was 4 hours ago then the issue has been around for 4 hours. If the system is in NOT PRODUCING state then we consider the newest readout, and walk backwards in time until we find a readout that is significantly different. Here we use the same algorithm used in site status determination, so if an explicit Minimum Production Threshold is set for the system, we use that, otherwise we calculate using the system DC size (or AC if DC is unavailable), or fall back on a fixed threshold of 5 kWh. So basically if the latest reading is 12345 kWh, and a fixed threshold of 5 kWh is set, then we backtrack until we find a reading less than 12340 kWh, and consider the outage to have started then.
Each of the two approaches to determine how long since the problem started has its merits and drawbacks. If we simply use the time then the system status changed, then we cannot run extra checks for example to see if the system is showing signs of life. However this way notifications are more consistent with system status, so clients don't question why an issue wasn't created even though the system has been in not producing state for a while. If we use the second "smart" method and determine when the last significant readout was acquired, then we can be more accurate in only creating issues if the system really requires attention, lowering false-flag notifications. For example, this way if we set up a new system and it takes Mana several days to acquire all historical readings for the system, then initially the system status will start to show that the system is Not Producing, but as long as we enable the extra checks, no issue will be created or notification sent out. Similarly, if a system stops communicating and goes into COM ERR, but then comes back online but initally reports very small readings, then the extra checks can help us to avoid unnecessarily creating a NOT PRODUCING issue.
Determining the time when the issue started is also important because this is important information for the client. So, when checking an issue, it is more important to understand when the last good readout was acquired than to know at what point in time Mana determined that the system status should be Not Producing or Com Err. With systems that have a large COM ERR timeout, a system can stop reporting hours or even days before the system status changes. An issue is then created but in the issue we want to see not the point in time when the system status changed, but the point in time when the system actually stopped reporting.
For some clients (currently NPC) we skip all extra checks and just consider how much time has elapsed since the system status deteriorated. For others we use the second "smart" approach
A site is down, yet no issue was created. Why?
If you suspect that an issue should have been created but wasn't, use the notification generation tool in simulation mode to see why the system isn't generating a notification:
- Log into the site as an administrator
- Open the site in question and navigate to the
Notificationstab - Click on the
Diagnosticsbutton - Make sure
Simulate Onlyis checked and clickGenerate Issues & Notifications
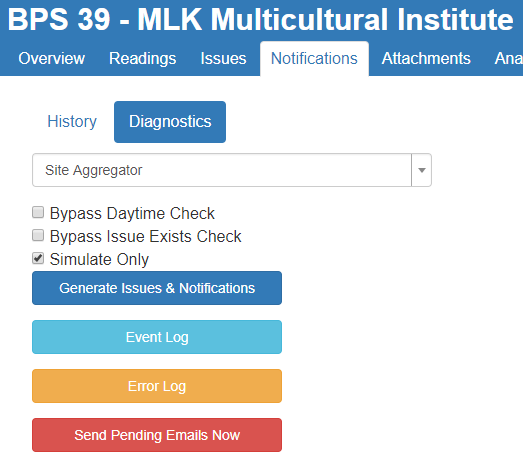
If it is nighttime at the site, the system will not generate an issue. Enable the Bypass Daytime Check option if you want to see if there is any other reason why the website hasn't generated an issue for the system.
If a user has already created an issue for the system, then the system will not automatically generate another one. Enable the Bypass Issue Exists Check option if you want to see if there is any other reason why the system hasn't generated an issue for the system.
If you do not wish to actually create an issue, make sure the Simulate Only option is checked.
The results of the issue generation are displayed with an explanation as to why an issue was or wasn't created:
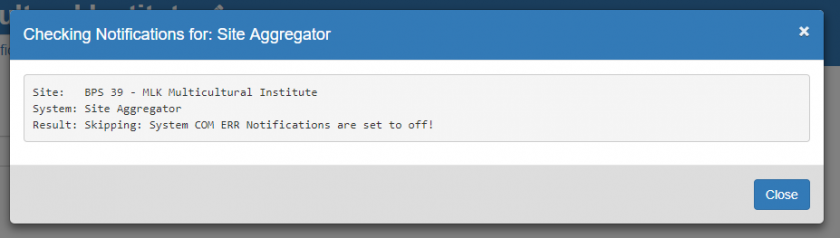
Review the event log
Use the Event Log button to review issue generation events related to the system selected:

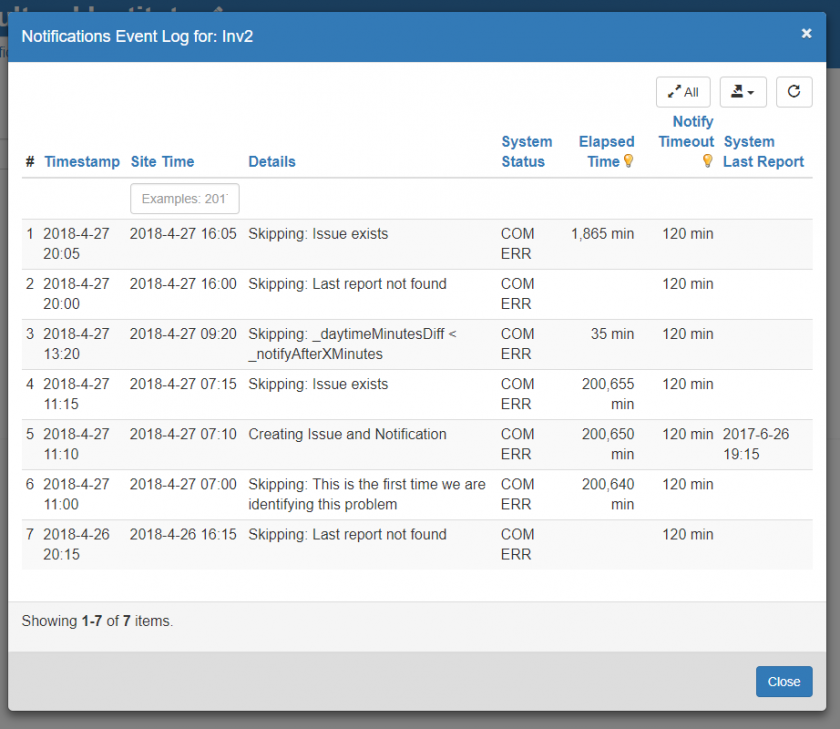
Note that the website does not record events if notifications are off for the given system. The following types of events are recorded:
-
Skipping: Irradiance low
No issue is created if irradiance checks are enabled and the site irradiance is under the irradiance threshold (which can be set independently for each site) -
Skipping: Not daytime
No issue is created if it is not "daytime" at the site; currently daytime is specified as "between 7 a.m. and 6 p.m." -
Skipping: Last report not found
If the system status is currently "COM ERR", then this means that the system has never reported any values; in such a case no issue is generated
If the system status if currently "NOT PRODUCING", then this means that the system has never reported any positive values; in such a case no issue is created -
Skipping: _daytimeMinutesDiff < _notifyAfterXMinutes
No issue is created until the specified timeout has elapsed. This timeout can be set for each system for COM ERR and NOT PRODUCING independently (see Setting the Issue Generation Timeout below). -
Skipping: Issue exists
No issue is generated if an open issue already exists for the given system. The following criteria are checked:- If the system status if NOT PRODUCING, and either a NOT PRODUCING or COM ERR type issue exists that was created by the system, no issue is generated
- If the system status if COM ERR, and a COM ERR type issue exists that was created by the system, no issue is generated
- If a user has created a COM ERR or NOT PRODUCING type issue after the system last report (i.e. after the problem started), then no issue is generated
-
Skipping: This is the first time we are identifying this problem
The system tries not to create an issue while readings are being loaded. This and the following two messages are related to this check. Specifically, if this is the first time we are identifying this problem (or the last time was a long time ago), we store the current reading in the `system` and skip, the next time around we will see if the reading is still the same...
-
Skipping: New readings have been loaded in the past 10 minutes
We have already checked this `system` over 10 minutes ago, but since then new readings have been loaded (for COM ERR), or new positive readings have been loaded (for NOT PRODUCING), so update the last reported time and check again 10 minutes from now... -
Skipping: Reload in progress...
We have already checked this system over 10 minutes ago, and no new readings have been loaded since, but a reload is in progress, so wait until at least 60 minutes have passed...
We know that a reload is in progress if more than one reading exists with the same sample time as the last reading (in case of COM ERR), or the last positive reading (in case of NOT PRODUCING). -
Skipping: Waiting at least 30 minutes before creating a NOT PRODUCING because the system was in COM ERR in the past hour...
We have already checked this system over 10 minutes ago, and no new readings have been loaded since, but the subsystem was in a COM ERR state in the past hour, so wait at least 30 minutes before creating a NOT PRODUCING issue. Basically, we try to give a system a bit of extra time to start reporting positive readings after it has come back from a COM ERR state before creating a NOT PRODUCING issue.
-
Creating Issue and Notification
All of the above exclusion conditions failed, therefore an issue is created for the system.
Error Log
Use the Error Log button to see if the system has encountered any errors during issue generation for the selected system.

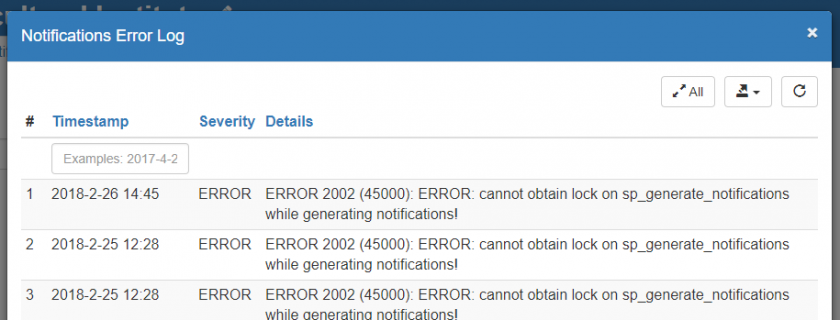
"Cannot obtain lock on..." type errors may occur from time to time and are usually not a cause for concern.
Send Pending Emails
The website automatically checks every few minutes if there are any pending emails awaiting delivery. However, you can force the site to check immediately for any such messages and to then send them using the Send Pending Emails button:

No Comments